“Metadata” just means the data about data – it’s the information about an object. As defined by Jenn Riley in “Understanding Metadata: What is metadata and what is it for? A Primer,” metadata is “the information we create, store, and share to describe things, [allowing] us to interact with these things to obtain the knowledge we need” (p. 1). For example, for an academic article, the metadata would include the article’s title, journal it was published in, authors, etc. It would also be the type of the material (article, audio clip), specific format (text, XML, MP4, etc.), and licenses or copyright.
While it seems relatively minor, it is very important to consider metadata in research! It helps others find, understand, and use content. Several major grant-funding institutions require that researchers make their data available to other researchers so they can verify claims and build on existing research.
This video from New York University’s Working with Research Data guide demonstrates the importance of metadata in research!
Types of Metadata
Riley (p. 6) defines three types of metadata:
- Descriptive metadata – Describing an object for the purposes of “finding or understanding a resource”
- Administrative metadata – Itself made up of:
- Technical metadata – “For decoding and rendering files”
- Preservation metadata – “Long-term management of files”
- Rights metadata – “Intellectual property rights attached to content”
- Structural metadata – “Relationships of parts of resources to one another”
Markup languages are often also included in discussions of types of metadata. These are tools that “[integrate] metadata and flags for other structural or semantic features within content” (6).
Uses of Metadata
Each type of metadata has a purpose, as outlined by Riley (p. 7):
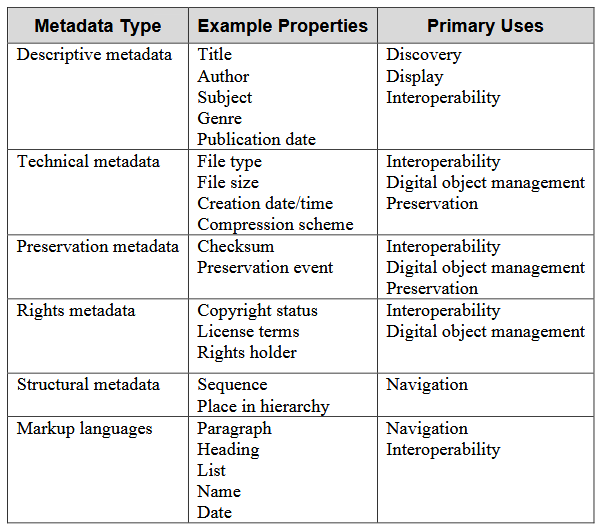
As you can see by this chart, the functions of metadata are what allow us to interact with information used in research, databases, anywhere that large stores of information is kept. Metadata is also what makes research data accessible and usable. It’s vital for researchers to have a solid plan for their metadata to ensure a consistent structure that can be understood well into the future.
Standards and Schemas
When planning how to collect and organize your research data, you may want to look for existing standards and schemas from the discipline you’re working with to ensure that your data is compatible with that of other researchers.
What are they?
Standards and schemas are used to maintain consistency in metadata across data sets (What is metadata? By Annie Badman and Matthew Kosinski, IBM).
Metadata standards “[define] how metadata should be structured and applied across different systems,” while a schema is “a blueprint for implementing metadata standards” (Badman & Kosinski). The standards are built on the principles provided in the schema.
Standards are developed based on different types of research. For example, a standard called Dublin Core is often used for digital resources across different disciplines. You can search the Digital Curation Centre by discipline for standards used in physical sciences, earth sciences, biology, or social sciences and humanities. Many of these standards have details on their correlating schemas available in the Extensions section, so that you can easily map your data into the structure.
Examples
Standards:
- Data Documentation Initiative (DDI) – commonly used in the social sciences, humanities, and economics
- Core Scientific Metadata Model (CSMD) – this is a “study-data oriented model, primarily in support of the ICAT data management infrastructure software” per CSMD page of the the Metadata Standards Catalog
- JavaScript Object Notation for Linked Data (JSON-LD) – based on the JSON format, this standard is used as a concept for the use of linked data
- NeXus – “an international standard for the storage and exchange of neutron, x-ray, and muon experiment data” according to the Digital Curation Centre’s page
Schemas:
- Common Information Model (CIM) – from the Metadata Standards Catalog, this “describes climate data, the models and software from which they derive, the geographic grids used to calculate and project them, and the experimental processes that produced them”
- EngMeta – used primarily in engineering, this schema provides “an XML-based formal definition of information necessary to find, understand, reproduce and reuse data” and is based on standards like “DataCite, PREMIS, ModeMeta and ExptML” – from the Metadata Standards Catalog page
- WaterML – a schema used for hydrology, profiling the Observations and Measurements standard
Controlled Vocabularies
Controlled vocabularies are types of descriptive metadata that can improve the findability of a resource, standardizing the language used for certain resources. There are several options available, depending on the type of description needed and the level of complexity required. As described in “Taxonomies and controlled vocabularies best practices for metadata” by Heather Hedden (2010), “a controlled vocabulary is a restricted list of words or terms typically used for descriptive cataloging, tagging or indexing” (p. 279). They are used to standardize the descriptions assigned to information.
Types of Controlled Vocabularies
The types of controlled vocabularies are:
- Term list – the simplest form, simply of list of options from which you can select the best fit; per Hedden, these “are often utilized for administrative and structural metadata elements, such as a list of possible file formats, rights status or retention status” (p. 279); however, they can also be used for descriptive fields in a dropdown or checkbox format
- Authority file – “includes synonyms or variants for each term which function as cross-references to guide the used from an ‘non-preferred term’ variant to the equivalent ‘preferred term’ (p. 280); used mostly with proper nouns
- Taxonomy – “a controlled vocabulary in which all the terms belong to a single hierarchical structure and have parent/child or broader/narrower relationships to other terms”
- Thesaurus – might be a dictionary-thesaurus or information/content retrieval thesaurus
- Information/content retrieval thesaurus – “[lists] similar terms at each controlled vocabulary term entry”; designed for all contexts; more structured “because it provides information about each term and its relationships to other terms within the same thesaurus”
- Dictionary-thesaurus – “all the associated terms might be used in place of the term entry spending upon the specific context, which the user needs to consider in each use”
Research Data Management
How does metadata relate to research data management?
It’s a vital component, ensuring that the information you capture in your data can be understood not only by you, but by others, both now and in the future.
You will need to decide what schema is necessary for the type of research data you’re collecting, then determine the most appropriate standard for your data. If you have a spreadsheet of data, it can be helpful to create a readme text file specifying the units, any equations used for calculations, etc. Imagine what someone with no background in your research project would need to know to understand your data and include any information that would help them.
Metadata in Research
A well thought-out, clearly communicated data management plan is vital prior to beginning your data collection. Before you even begin the process of acquiring and organizing your data, you will know how to format and organize it, which will then ensure that other researchers can find and use your data. This is mandatory for several grants, such as those through the National Institute of Health and National Science Foundation. This allows for other researchers to confirm your research is reproducible (there is currently a reproducibility crisis in academic research) and can be expanded on to allow for more growth within the field.
Metadata should be FAIR (aligning with the FAIR Principles):
- Findable – Metadata should describe data and research sufficiently that it can be found by people and computer programs, which often means being text-based (especially important for non-textual results like images, videos, audio, etc.).
- Accessible – The metadata should indicate how the data can be accessed, including whether authentication or authorization are necessary. Additionally, the metadata should still be available when the data itself is not.
- Interoperable – The format of the data needs to be explicitly stated and should be available in the most universal format possible so that use by others is not limited. Other researchers should know how you formatted your data so they can make any necessary changes to integrate the data into their own processes for analysis.
- Reusable – The primary goal of FAIR Principles is to allow others to use research data so that your research focus can be built up. Your metadata should include clear labels for any licenses your data is subject to. If there are any discipline-specific standards researchers adhere to, you should do so also and include that information in your metadata.
Data Management Plan
A Data Management Plan (DMP) outlines the collection and treatment of research data throughout its lifecycle, including after your research is over. A formalized plan may be required for certain grants, but even for research without a grant, it’s helpful to have this information available before beginning research.
Per the Duke University Libraries research guide on Research Data Management, a Data Management Plan typically “includes a description (provides subject scope and scale), probable formats, metadata, how the data will be stored, secured and backed-up, who will be primarily responsible for the care of the data, and how the data will be preserved and shared with a broader audience” (from the Data Management Plans section).
You will need to decide if you are going to use any standards or schemas and whether there are any controlled vocabularies that would be appropriate for your project.
The University of Reading provides a detailed Data Management Planning guide through their Research, Engagement and Innovation Office. Additional sections discuss every step of the process of managing and preserving research data along with data sharing.
Additional Resources
- Metadata & Discovery @ Pitt – University of Pittsburgh Library guide
- Data Management @ Pitt – University of Pittsburgh Library guide
- Metadata Basics – University of Texas Libraries guide
- Metadata for Data Management: A Tutorial – University of North Carolina Library guide
- What is Research Data Management – Harvard Medical School guide
- Research Data Management – University of Virginia Library guide